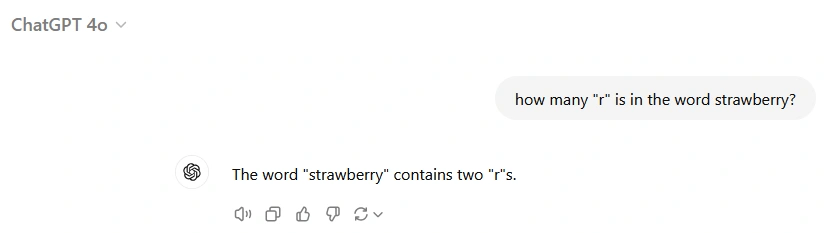
Before you mock ChatGPT for making a low-level mistake, there's actually an important concept behind the scenes—token—a fundamental element in modern Large Language Models (LLMs). Tokens are also the units by which AI platforms charge you money for using their API. But why should designers and engineers care? Because without mastering the basics, you might misapply a tool that is supposed to save you from pulling an all-nighter. Don't let AI remain a mere chatbot for fun.
Tokens are the basic units of text that LLMs use to interpret and generate language. They aren't always whole words; instead, they can be words, subwords, or even individual characters, depending on the tokenization strategy employed. For instance, the word "strawberry" might be broken down into tokens like "straw" and "berry," or even smaller units.
Here's a curious phenomenon: when asked how many times the letter "r" appears in "strawberry," some AI models might provide an incorrect answer. This isn't because the models lack basic counting abilities but because of how they tokenize the word internally. If "strawberry" is tokenized into larger chunks like "straw" and "berry," the model may not account for individual letters within those tokens when performing operations like counting specific characters.
P.S.: The latest versions (like ChatGPT-o1) have already overcome this problem. LLM models evolve at a speed no human can match. While you may not be able to learn faster than AI, you can certainly stay ahead of most of your peers by keeping up.